我测了40个国产 AI Coding 模型的推理速度,同款模型渠道不同速度差 2.5 倍
实测阿里、腾讯、字节、MiniMax、Kimi 等40个 AI Coding 模型的 TTFT 和 Tokens/s,同款模型不同渠道速度差距超 2.5 倍。附各厂商 Coding Plan 订阅入口。
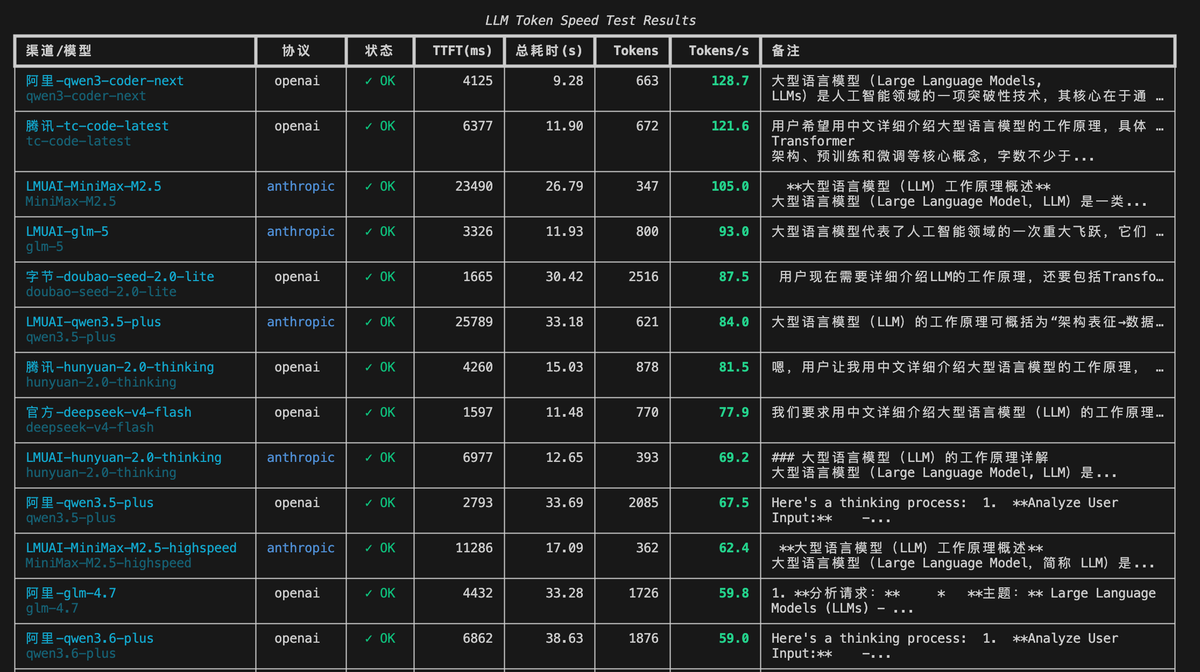
测试时间:2026年4月 | 有效测试:38条 | 未纳入:百度(API 失效)、讯飞(频繁限流)
做 AI 辅助编程久了,速度是一个绕不开的问题。模型再好,TTFT 超过 10 秒就会破坏心流。
这次测试了阿里、腾讯、字节、MiniMax、Kimi、DeepSeek 等主流厂商的 Coding 模型,同时对比了通过灵眸AI中转接入的同款模型,想搞清楚:接入渠道对速度的影响到底有多大?
测试说明
Prompt: 用中文详细介绍大型语言模型工作原理(500字以上,含 Transformer、预训练、微调)
指标:
- TTFT:首 token 延迟(ms),决定"等待感"
- Tokens/s:输出速度,决定长代码生成的流畅度
关于灵眸AI: 测试中标注"灵眸AI"的条目,均为通过灵眸AI API 中转接入的模型。灵眸AI 不只转发 Claude,也提供国内主流模型的统一 API 接入,本次测试顺带验证了它在各模型上的速度表现。
⚠️ 免责说明: 以下测试数据均为单次采样,AI 平台的推理速度受服务器负载、网络状况、时间段等因素影响,不同时间段测试结果可能有较大差异。本文数据仅供参考,不能作为平台选择的决定性依据,建议自行测试后再做决定。
完整速度榜单(按 Tokens/s 排序)
| 排名 | 渠道 · 模型 | TTFT(ms) | Tokens/s |
|---|---|---|---|
| 🥇 | 阿里 · qwen3-coder-next | 4125 | 128.7 |
| 🥈 | 腾讯 · tc-code-latest | 6377 | 121.6 |
| 🥉 | 灵眸AI · MiniMax-M2.5 | 23490 | 105.0 |
| 4 | 灵眸AI · glm-5 | 3326 | 93.0 |
| 5 | 字节 · doubao-seed-2.0-lite | 1665 | 87.5 |
| 6 | 灵眸AI · qwen3.5-plus | 25789 | 84.0 |
| 7 | 腾讯 · hunyuan-2.0-thinking | 4260 | 81.5 |
| 8 | 官方 · deepseek-v4-flash | 1597 | 77.9 |
| 9 | 灵眸AI · hunyuan-2.0-thinking | 6977 | 69.2 |
| 10 | 阿里 · qwen3.5-plus | 2793 | 67.5 |
| 11 | 灵眸AI · MiniMax-M2.5-highspeed | 11286 | 62.4 |
| 12 | 阿里 · glm-4.7 | 4432 | 59.8 |
| 13 | 阿里 · qwen3.6-plus | 6862 | 59.0 |
| 14 | 腾讯 · hunyuan-t1 | 2801 | 55.8 |
| 15 | 字节 · doubao-seed-2.0-pro | 2960 | 55.6 |
| 16 | 灵眸AI · qwen3.6-plus | 26170 | 56.4 |
| 17 | 阿里 · qwen3-coder-plus | 3982 | 52.5 |
| 18 | MiniMax-M2.7-highspeed(直连) | 13940 | 50.3 |
| 19 | 腾讯 · minimax-m2.5 | 9198 | 48.0 |
| 20 | 阿里 · kimi-k2.5 | 5243 | 44.7 |
| 21 | MiniMax-M2.5(直连) | 26490 | 42.1 |
| 22 | 灵眸AI · MiniMax-M2.7-highspeed | 9741 | 41.9 |
| 23 | 字节 · doubao-seed-code | 6062 | 37.6 |
| 24 | 腾讯 · hunyuan-2.0-instruct | 5130 | 35.6 |
| 25 | 灵眸AI · claude-sonnet-4-6 | 28910 | 35.3 |
| 26 | 字节 · doubao-seed-2.0-code | 2633 | 35.0 |
| 27 | 腾讯 · kimi-k2.5 | 3309 | 30.3 |
| 28 | 灵眸AI · claude-opus-4-6 | 21704 | 28.6 |
| 29 | 腾讯 · glm-5 | 2329 | 27.1 |
| 30 | 灵眸AI · doubao-seed-code | 3389 | 26.6 |
| 31 | 腾讯 · hunyuan-turbos | 3182 | 25.0 |
| 32 | 字节 · deepseek-v3.2 | 5828 | 24.9 |
| 33 | 灵眸AI · deepseek-v3.2 | 7844 | 23.4 |
| 34 | Kimi-k2.5(直连) | 2507 | 22.8 |
| 35 | 灵眸AI · kimi-k2.6 | 4403 | 22.0 |
| 36 | 灵眸AI · kimi-k2.5 | 11796 | 21.5 |
| 37 | 字节 · glm-4.7 | 4638 | 12.3 |
| 38 | 字节 · kimi-k2.5 | 4940 | 8.2 |
四个关键发现
发现一:同款模型,接入渠道不同速度差距悬殊
这是本次测试最出乎意料的结论。以 MiniMax-M2.5 为例,同一个模型通过不同渠道接入,Tokens/s 差距巨大:
| 接入渠道 | Tokens/s | 相对速度 |
|---|---|---|
| 灵眸AI 接入 | 105.0 | 基准 |
| MiniMax 官方直连 | 42.1 | 40% |
| 腾讯渠道 | 48.0 | 46% |
| 字节渠道 | 32.8 | 31% |
灵眸AI 接入的 MiniMax-M2.5 速度是官方直连的 2.5 倍。这说明中转层的链路路由对速度影响很大,并不是所有渠道都平等。
glm-5 也有类似规律:
| 接入渠道 | Tokens/s |
|---|---|
| 灵眸AI 接入 | 93.0 |
| 阿里渠道 | 36.5 |
| 腾讯渠道 | 27.1 |
但灵眸AI 并不是所有模型都最快——hunyuan-2.0-thinking 通过腾讯自家接入(81.5 t/s)快于灵眸AI(69.2 t/s),deepseek-v3.2 官方版(24.9 t/s)也略快于灵眸AI 接入(23.4 t/s)。模型原厂直连在部分场景下有天然优势。
发现二:TTFT 和 Tokens/s 是两个完全独立的维度
需要分开来看,不能混为一谈:
首 token 最快(TTFT < 2s)
| 模型 | TTFT | Tokens/s |
|---|---|---|
| 官方 · deepseek-v4-flash | 1597ms | 77.9 |
| 字节 · doubao-seed-2.0-lite | 1665ms | 87.5 |
这两个是交互体验最好的——几乎没有等待感,适合频繁短问答。
输出最快但 TTFT 慢(>20s)
| 模型 | TTFT | Tokens/s |
|---|---|---|
| 灵眸AI · MiniMax-M2.5 | 23490ms | 105.0 |
| 灵眸AI · qwen3.5-plus | 25789ms | 84.0 |
首 token 需要等 20 多秒,但一旦开始输出就非常快,适合一次性生成大段代码的场景。
实际选择建议:
- 频繁短对话 / 代码补全 → 优先看 TTFT,选 deepseek-v4-flash 或 doubao-seed-lite
- 长代码生成 / 完整文件输出 → 优先看 Tokens/s,总耗时更短
发现三:Coding 专用模型显著领先通用模型
前两名都是专为编程优化的模型:
- qwen3-coder-next(阿里):128.7 t/s
- tc-code-latest(腾讯):121.6 t/s
同期阿里的通用旗舰 qwen3-max 只有 28.7 t/s。Coding 专用模型速度是通用旗舰的 4–5 倍,在纯代码生成场景下性价比更高。
发现四:字节跳动渠道部分模型速度严重异常
字节渠道的 kimi-k2.5 只有 8.2 t/s,是整个榜单最慢的——115 秒才输出 900 token。glm-4.7 也只有 12.3 t/s,总耗时接近 60 秒。
同款 kimi-k2.5 通过其他渠道速度正常(腾讯渠道 30.3 t/s,直连 22.8 t/s),说明不是模型本身的问题,而是字节侧的调度或限速策略导致的。字节渠道适合调用字节自家的 doubao 系列,跑其他厂商的模型体验较差。
失败记录
以下平台未能纳入有效数据:
- 百度千帆:所有模型返回
invalid_iam_token401,套餐退订后 Key 失效 - 讯飞星火:
AppIdQpsOverFlowErrorQPS 超限,免费额度极少,稍微多测几次就报错,已退订 - 智谱 GLM-4-Flash:未配置 Key,跳过
百度和讯飞体验差的核心原因是免费配额太少,不适合作为主力开发渠道。
选型建议
场景一:AI Coding 速度优先,预算有限
→ qwen3-coder-next(阿里直连)或 tc-code-latest(腾讯直连),128 t/s 以上,专用 Coding 模型
场景二:国产模型 + 低 TTFT
→ deepseek-v4-flash(官方直连),1.6s 首 token + 77.9 t/s,交互体验好
场景三:通用模型 + 统一接入多家
→ 可以考虑聚合型中转平台,同时支持多厂商模型,减少多套 Key 的管理成本
场景四:Claude Code 主力
→ 通过支持 Prompt Cache 的中转站接入,价格和缓存支持是核心考量,详见比价工具
各厂商 Coding Plan 订阅入口
各平台均提供针对 AI 编程场景的专项套餐,通常比按量计费更便宜,建议按需订阅:
| 平台 | Coding Plan 订阅地址 |
|---|---|
| 百度千帆 | console.bce.baidu.com |
| 字节火山引擎 | console.volcengine.com |
| 阿里云百炼 | bailian.console.aliyun.com |
| 腾讯云 | console.cloud.tencent.com |
| 科大讯飞 MaaS | maas.xfyun.cn |
| MiniMax | platform.minimaxi.com |
注:百度和讯飞本次测试未能纳入有效数据(见失败记录),但套餐订阅后速度表现可能与本次结果不同,建议小额试用后再决定。
价格 × 速度:不能只看一边
速度测试只是一个维度,结合价格才有意义。各平台的 token 真实价格(换算汇率后)差距可达 3 倍,可以用这个工具自己算:
源码开源:https://github.com/LMU-AI/ai-api-price-calculator
测试时间:2026年4月
单次测试数据,速度受服务器负载影响,仅供参考
有其他平台数据欢迎评论区补充
利益相关说明:本文包含灵眸AI 推广链接,注册后作者可能获得返佣。测试数据为客观实测,其他平台无利益关系。


